The TIPS project is based on the idea of using mass media and online newspapers, in particular, as a source for analysing the way science and technology is represented in the public sphere in order to study the role of techno-science in society, its relevance and evolution. To fulfil these aims, TIPS is grounded on a purpose built ICT infrastructure. Its design includes a dedicated platform capable of collecting, sorting and automatically analysing the text of newspaper articles in their digital format. These texts are then indexed and stored in a database for research analysis1.
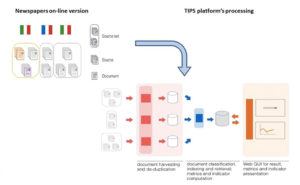
The TIPS platform is currently monitoring the eight most important Italian newspapers and, in a time span ranging from 2010 to yesterday, approximately 1.2 million articles have been collected. In 2014 the TIPS platform also began collecting two UK, two US, one Indian and seven French newspapers thus adding a further 1.4 million articles to its database. By means of ‘classifiers’ specifically developed by the TIPS research group, the platform determines whether the content of each article pertains to the science and technology domain. Then each article stored in the database is ‘tagged’ so that it is available for further analysis with an even greater focus on specific research questions.
The TIPS platform also calculates ad-hoc techno-science presence indicators and metrics within the main Italian daily newspapers: its ‘salience’ (i.e. the relative weight of techno-science in all the published articles in a given time span), ‘prominence’ (i.e. its presence on the home page) and its ‘presence’ outside newspaper sections specifically devoted to science and technology. The platform also provides a ‘risk indicator’, a measure expressly developed to operationalise risk as an ontological analytical dimension of public techno-science related discourse (figure 2).
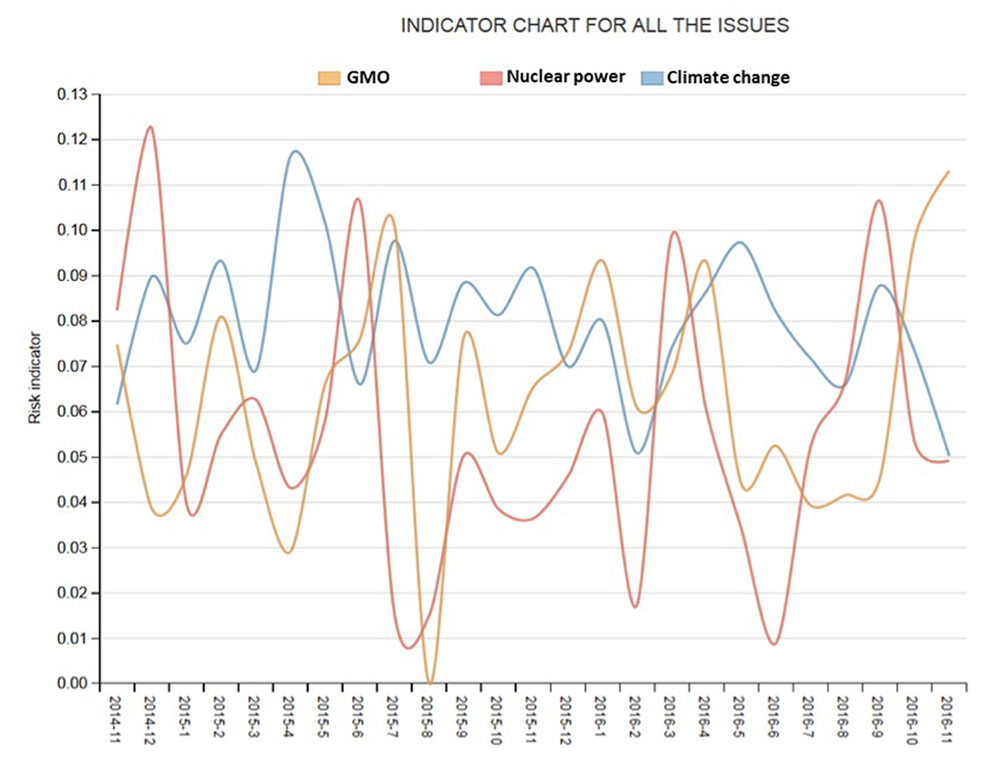
So far, the research on techno-science in the media has generated a great deal of work on quite a wide range of issues including, of the most significant, climate change, genetically modified organisms, cloning, stem-cells, digital innovation and health risks. A majority of these analyses has focused largely on a limited portion of news, i.e. those specifically regarding a given issue, even if, alternatively, there have been also studies based on samples designed to map the presence of techno-science as a whole and thus to study its representation as well as to outline the perspectives of the social actors involved.
By contrast, TIPS was designed to take a non-specific topic-oriented approach. Rather than focusing on a restricted set of research topics, the objective is to follow techno-science coverage as a whole over time, enabling researchers to examine specific topics of interest. Accordingly, one of the most important methodological novelties generated by the TIPS project regards its infrastructure. The latter was designed to collect and analyse newspaper articles on a daily basis allowing researchers to analyse whole sets of online newspaper articles and texts.
The TIPS project roots its epistemological assumptions in recovering STS key-concepts. As techno-science resumes all the elements interwoven in processes of science and technology production and circulation (Latour 1987, pp. 174-175), TIPS assumes it as main concept to orient its monitoring activities. Indeed, from an empirical point of view, considering techno-science as an epistemic category enables researchers to avoid the need for univocal definitions (Shapin 2008, p. 3), keep their minds open to those processes and be flexible enough to intercept emerging trends about what are not yet ‘scientific facts’. The approach chosen by TIPS – i.e. considering the news as a whole using automated content analysis, comparing the features of specific issues against those of other issues or against media coverage as a whole – offers a perspective which embodies these key STS assumptions. However, this ‘operational openness’ has to be balanced with robust classification criteria. Indeed, in so far as TIPS aims to monitor techno-scientific issues, it first needs to establish clear criteria with which to identify techno-scientific content in a newspaper article. STS concepts, such as science as situated activity, the agency of non-human actors (artefacts, research tools, infrastructure etc.) definitely contributed to setting up useful demarcation elements as a reference for building up the classifiers, the indicators and the metrics used by TIPS.
Early outcomes of the project have been presented in international venues such as workshops in Stellenbosch (South Africa), Salvador de Bahia (Brazil) and Istanbul (Turkey), besides STS Italia and International Sociological Association conferences. In these, indicators and indexes as well as research outcomes were discussed showing techno-science salience trends and selected issue coverage. The relationship between media coverage and public opinion has been also explored, as in the case of recently published work on the nuclear power controversy which compares TIPS risk indicators from newspapers with public opinion perceived risk data (Neresini and Lorenzet 2016).
The operationalization of STS concepts into a media monitoring project is a first step in the hybridization between different, even related, scientific debates. The entire research group, however is a hybrid. Within TIPS this partnership has moved it in the direction of genuine interdisciplinary project organization involving scholars with sociology, linguistics, social psychology, statistics and ICT backgrounds. As Evans and Aceves (2016) have recently argued “machine learning is enabling the translation of text into social data” and this is the perspective TIPS is exploring further. This interdisciplinary cooperation is taking technical aspects about how properly to clean and interrogate data, for instance, further by making machine learning features such as ‘topic modelling’ (Blei 2012), ‘Named Entity Recognition (NER)’, and ‘part of speech (POS) tagging’ available for analysis. This interdisciplinary environment has proved to be ideal for tailoring and validating classification tools in the custom development of TIPS infrastructure. Machine Learning tools such as the Support Vector Machine (Cristianini and Shawe-Taylor 2000), for instance, have been crucial to positively testing the trustworthiness of the TIPS thesaurus-based classification scoring system. Interdisciplinary cooperation has further web-data automated monitoring development potential.
Indeed, the research team is presently working on a variety of topics related to technical aspects of content analysis by means of text mining. A further future development is investigating the potential for including the ‘corpus linguistics’ approach (Biber et al. 1998) as a possible feature for cross-linguistic and longitudinal analysis.
The TIPS team is therefore actively dedicated to exploring how the so-called ‘data science’ epistemological discontinuity (Kitchin 2014) may bring a better understanding of techno-science in the public sphere. Future developments generated by this epistemic potential will relate to both cross-country and source comparison. For the former, automated text classifiers for English and French are already in the pipeline. The latter, which will enlarge the analytical spectrum to social networks and blogs, is at an advanced level as TIPS is presently collecting approximately a thousand blog posts per day.
The ever increasing volume of data available for the purposes of virtually analysing any topic whatsoever, not only those linked to techno-science, is a stimulating challenge that still requires multiple skills and in-depth cross-fertilization between concepts, theoretical models and approaches ranging across various disciplines.